⚙️ StyleVAR: Controllable Image Style Transfer via Visual Autoregressive Modeling
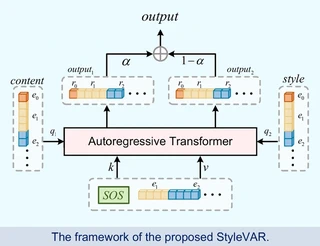 Image credit: Jing et al., 2025
Image credit: Jing et al., 2025Welcome to our project blog 👋
Table of Contents
Overview
Reference-based image style transfer aims to generate an image that preserves the spatial layout and object semantics of a content image while adopting the colors, textures, and local patterns of a style image. This technology is valuable for artistic creation, visual prototyping, and controllable data augmentation.
However, traditional methods often struggle to balance the trade-off between content preservation and style strength. Furthermore, modern diffusion-based approaches, while powerful, often suffer from slow sampling speeds and high computational costs due to iterative denoising steps.
In this project, we introduce StyleVAR, a framework built upon Visual Autoregressive Modeling (VAR). We formulate style transfer as conditional discrete sequence modeling in a multi-scale latent space, introducing a novel attention mechanism to effectively blend style and content.
The Core Problem
Balancing content preservation and style strength presents fundamental challenges. If a model focuses too much on content, the stylization becomes weak; if it overemphasizes style, it may distort object shapes or introduce artifacts that break semantic coherence. Additionally, styles vary widely—from global tone changes to fine-grained textures—requiring a robust method to combine information effectively.
Our Solution: Blended Cross-Attention
To address these challenges, we developed a Blended Cross-Attention mechanism. This allows the evolving target representation to attend to its own history while using style and content features as queries to determine which aspects of that history to emphasize.
Key Innovations
- Conditional Discrete Sequence Modeling: Images are decomposed into multi-scale representations and tokenized into discrete codes by a VQ-VAE. The target image is generated scale by scale, conditioned on the history of generated tokens as well as style and content tokens.
- Blended Cross-Attention: We assign the target feature history to the Key ($K$) and Value ($V$) roles, while assigning style and content features to the Query ($Q$) role. This ensures the model aggregates information from the target’s own past (preserving autoregressive continuity) while being guided by the conditions.
- Scale-Dependent Blending: A blending coefficient $\alpha$ controls the relative influence of style and content at each stage.
Technical Implementation
Mathematical Formulation
The generation of the target image $R$ proceeds in a scale-wise autoregressive manner, modeled by the following probability distribution:
$$ P(x|x_s, x_c) = \prod_{k=1}^{K} P(r^k | r^{1:k-1}, s^k, c^k) $$Within each transformer block, the feature update process utilizes our blending strategy:
$$ h_{new} = h + [\alpha \cdot \text{Attn}(Q=s^k, K=h, V=h) + (1-\alpha) \cdot \text{Attn}(Q=c^k, K=h, V=h)] $$Here, $\alpha$ is a hyperparameter governing the blending ratio, and $h$ represents the input target features acting as both Keys and Values.
Training Setup
We initialized StyleVAR using a pre-trained vanilla VAR model checkpoint. The VQ-VAE component was frozen, while the 600M parameters of the transformer were fine-tuned for 8 epochs on two NVIDIA A100 GPUs. We utilized the OmniStyle-150K dataset, consisting of approximately 150k triplets of content, style, and target images.
Experimental Results
We benchmarked StyleVAR against the AdaIN baseline on 500 randomly selected style-content pairs.
Quantitative Metrics
Our method demonstrated superior performance in preserving content and structure compared to AdaIN:
- Content Preservation (Content Loss): 119.94 (StyleVAR) vs. 177.23 (AdaIN).
- Structure Preservation (SSIM): 0.3224 (StyleVAR) vs. 0.1884 (AdaIN).
- Perceptual Distance (LPIPS): 0.6297 (StyleVAR) vs. 0.7712 (AdaIN).
While AdaIN is faster (317.97 FPS vs. 2.48 FPS), StyleVAR achieves significantly better perceptual quality and structural fidelity.
Qualitative Analysis
Visual results indicate that StyleVAR successfully transfers texture while maintaining semantic structure, particularly for landscapes and architectural scenes.

Impact & Future Work
Despite strong performance, we observed a generalization gap when testing on unseen internet images and difficulties with human faces. This is likely due to the limited number of unique content images (~1,800) in the training set.
To address this, our future roadmap includes:
- Data Diversification: Expanding the training data with more diverse content images, specifically in challenging domains like human faces.
- Classifier-Free Guidance: Implementing a mechanism to adjust style strength at inference time, turning style influence into a continuous dial.
- GRPO-Driven Unsupervised Learning: We plan to explore Group Relative Policy Optimization (GRPO) to fine-tune the model using perceptual rewards (e.g., VGG loss) without relying on paired ground truth.
Citation
If you find this work useful for your research, please cite our project:
L. Jing, D. Zhang, and P. Li, “StyleVAR: Controllable Image Style Transfer via Visual Autoregressive Modeling,” Duke University Course Project, Dec. 2025.

I am currently a Master’s student in Electrical and Computer Engineering at Duke University, maintaining a 4.0 GPA. My research centers on Vision Language Models, Generative AI and Autonomous Driving.
My recent work involves developing StyleVAR, an autoregressive transformer framework for controllable image style transfer. I have also gained industrial research experience at Bosch, where I worked on enhancing VLM grounding capabilities using Reinforcement Learning (GRPO) and data distillation.
Beyond the algorithms, I am an audiophile and a gamer. I enjoy the engineering challenge of building Hi-Res audio systems from scratch—pursuing high fidelity in sound just as I pursue precision in model generation.